
Welcome to HDL Express, the personal webpages of Kirk Weedman
HDL stands for Hardware Description Language.
This website also contains information on various Verilog/FPGA tutorials, Alternative Energy projects, and the progress of a new CPU architecture that I'm designing.
I'm an electronic design engineer specializing in contract Verilog, System Verilog RTL FPGA design, functional verification, testbench creation, Assertion Based Verification, Formal Verification, simulation, debug, etc.. I have a varied background in other disciplines too.
My resume: Download the PDF version here. Download Word format here
---------------------------------------------------------------------------------------------------------------------
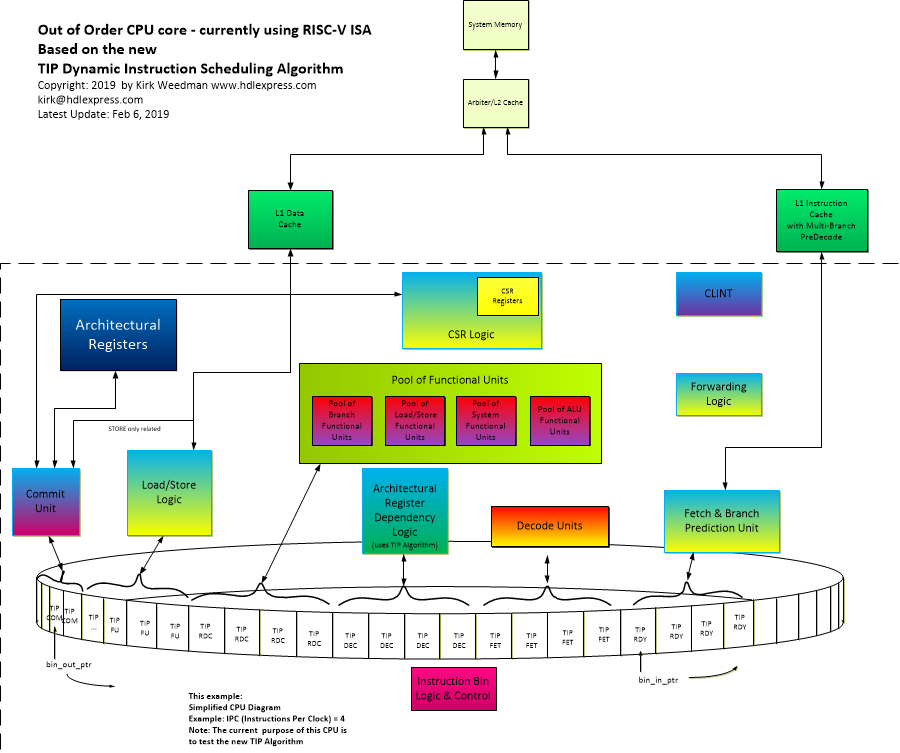
A new dynamic instruction scheduling algorithm - the TIP Algorithm
Dec, 2019: Current Status of the new Out of Order CPU Architecture based on the TIP algorithm
Currently taking a break from this OoOE CPU and actively working on my open-source RisKy1 Project.
This new dynamic instruction scheduling algorithm is not like the typical OoO methods being used today and the goal is to improve OoO IPC. Many modern Out of Order CPU's, asre based on the Tomasulo or Scoreboarding algorithm (or some variant) for dynamic instruction scheduling. The method used in this CPU is different and simpler although there are several very specific rules it follows. One interesting affect about the method is that no register renaming is needed.
In the present implementation there is a circular queue/bufffer that holds the last N instructions. This buffer is quite different in that it acts as a Fetch buffer, Reservation Station for pending Out of Order scheduling to F.U.'s, the Load/Store buffer for In Order Storing and Out of Order Loads, and it also serves as a buffer for In Order Retirement.
It appears that as IPC increases linearly, the logic for the this new algorithm grows fairly linear instead of exponentially like the Tomasulo algorithm. The goal of building a working CPU is to prove the method works and to vary design parameters to get maximum performance (IPC throughput) for a given microarchitecture. The design is highly parameterized to allow many variations in the design. The latest design is now written in System Verilog RTL.
4/27/2017 - Since this algorithm can be applied to most any ISA, I am switching from the ARMv7 ISA to the RISC-V (RV32IM). RISC-V will be simpler to implement and there is software tool support for it.
See CPU History for more information about the progress on this architecture
Feb 6 2019 - New block diagram of latest CPU arhitecture for testing the new TIP Dynamic Instruction Scheduling Algorithm. Although the architecture for this "test bed" CPU has gone through several changes, the TIP Algorithm has not changed and appears to be working well.
1. Load/Store version 3 logic - Mar 24, 2019
2. RV32C Compressed instruction set completed - needs testing
3. Fetch predecode logic completed - needs more testing
4. Debugging RISC-V CSR instructions
5. New L1 Instruction and Data Caches being tested.
6. Various functional unit simulations going on - only simple branch prediction has been added so far
7. Will begin adding Branch Prediction Logic. (only rudimentary BPL at present - code is already set up for adding BPL)
unique visitors since Mar. 3, 2016
Fast Counters
![]()